range([start,] stop[, step]),根据start与stop指定的范围以及step设定的步长,生成一个序列。
|
|
xrange 用法与 range 完全相同,所不同的是生成的不是一个list对象,而是一个生成器。
|
|
技术面前,永远都是学生。
range([start,] stop[, step]),根据start与stop指定的范围以及step设定的步长,生成一个序列。
|
|
xrange 用法与 range 完全相同,所不同的是生成的不是一个list对象,而是一个生成器。
|
|
python for循环可以遍历任何序列的项目,如一个列表或者一个字符串
for循环的语法格式如下
|
|
流程图

python编程中while语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要从父处理的相同任务。基本形式为
|
|
执行语句可以是单个语句或语句块。判断条件可以是任务表达式,任何非零、或非空(null)的值均为Ture。
当判断条件假False时,循环结束。
执行流程图如下:

计算机之所以能做很多自动化的任务,因为它可以自己做条件判断。
python条件语句是通过一条或多条语句的执行结果(true或者false)来决定执行的代码块。
可以同坐下图来接单了解条件语句的执行过程:

python程序语言指定任何非0或非空(null)值为true,0或者null为false。
python编程中if语句用于控制程序的执行,基本形式为
|
|
python之所以如此简单,归功于它的缩进机制,严格的缩进机制使得代码非常整齐规范,提高了可读性,在一定意思上提高了可维护性。代码十分严格的缩进格式,如果不按照贵局办事,一不小心就会出现语法错误。
对于python而言代码缩进是一种语法,python并不像其他语言那样要求什么{}或者begin…end分割代码块,而是采用代码缩进和冒号来区分代码之间的层次。
缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
|
|
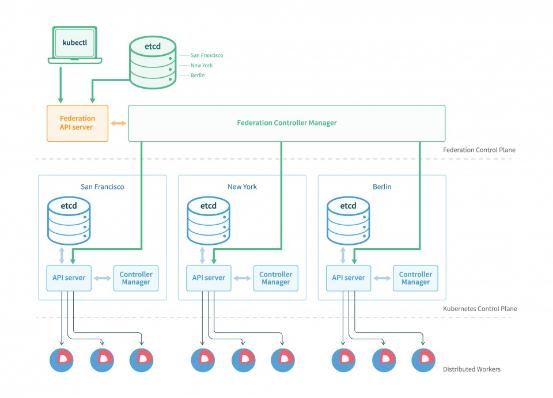
Kubernetes在1.3版本之后,增加了“集群联邦”Federation的功能。这个功能使企业能够快速有效的、低成本的跨区跨域、甚至在不同的云平台上运行集群。这个功能可以按照地理位置创建一个复制机制,将多个kubernetes集群进行复制,即使遇到某个区域连接中断或某个数据中心故障,也会保持最关键的服务运行。在1.7版以后支持本地多个集群联邦管理,不需要使用依赖云平台。
“集群联邦”在架构上同kubernetes集群很相似。有一个“集群联邦”的API server提供一个标准的Kubernetes API,并且通过etcd来存储状态。不同的是,一个通常的Kubernetes只是管理节点计算,而“集群联邦”管理所有的kubernetes集群。
要查看python的变量属于哪个数据类型的时候,可以使用type(variable)
|
|
字典是另一种可变容器模型,切可存储任意类型对象。
字典是Python中唯一的映射类型(哈希表)
字段对象是可变的,但是字典的键必须使用 可变对象 ,一个字典中可以使用不同类型的键值。
python内置了字典:dict的支持,dict全称dictonary,在其他语言中也成为map,使用键-值(key-value)存储,具有几块的查找速度。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中,格式如下所示:
|
|
例:假设要根据人名查找对应的成绩,如果列表实现,需要两个列表
|
|
另有一种有序列表叫元组(tuple)。元组和列表非常类似,但是元组一旦初始化就不能修改,
元组是序列的一种。序列包括字符串、列表和元组。
|
|
现在,classmates这个元组不能变了,它没有append(),insert()这样的方法。其他获取元素的方法和列表是一样的classmates[0],classmates[-1],但不能赋值成另外的元素。
因为元组不可变,所以代码更安全。如果可能,能用元组列表就尽量用元组。
元组的陷阱:当定义一个元组时,在定义的时候,元组的元素就必须被确定下来。
|
|